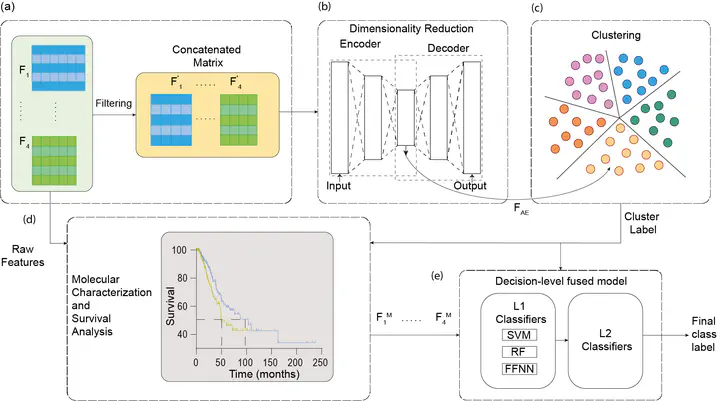
 Outline of pipeline
Outline of pipelineIn this study, an autoencoder based approach is followed to non-linearly project high-dimensional multi-omics (mRNA, miRNA, methylation, and protein expression) non-small cell lung cancer (NSCLC) data to a lower dimensional space. The compressed data is then subjected to consensus k-means clustering to identify the clusters. Survival analysis of the resulting clusters revealed a significant difference in overall survival (p: 0.019, p: 0.169 for PCA based approach). Furthermore, molecular characterization of these subgroups using ANOVA, Tukey’s post-hoc test, and limma applied to each omic level, revealed that the group with the longest survival time had fewer genomic changes. To predict the subgroup of unseen patients, classification models (base classifiers) and their ensemble (linear and non-linearly combined base classifiers) with input features selected based on ANOVA, Tukey’s post-hoc test, limma, and fold-change (FC) from each omic level are built. Furthermore, the base classifiers along with the ensemble models are also built for various combinations of single-omic data. It is observed that multi-omics outperforms single-omic analysis, and the combination of classifiers proves to be a more accurate prediction model than the individual classifiers.
Seema Khadirnaikar
Research Scholar
My research interests include application of supervised and unupervised machine learning techniques to precision medicine.